


數控機床熱(rè)誤差補償模型(xíng)穩健性比較分析
2015-12-18 來源:數控機床市場網 作者:合肥工業(yè)大學儀器科學(xué)與光電工程(chéng)學(xué)院苗恩銘
摘要:數學模型的精度特性和穩健性特性對數控機(jī)床熱誤差補償技(jì)術在實際中的實施性(xìng)影響不容忽視。論(lùn)文對數控加工(gōng)中心關鍵點的溫度和主軸 z 向的熱變形量采(cǎi)用多種算法建立了預測模型,對不同算法擬合精度進(jìn)行分析。同時(shí)全年(nián)進行熱誤差跟蹤試驗,獲(huò)得了機床在不同環境溫度和不同主軸轉速的試驗條件下的敏(mǐn)感點溫度(dù)和熱誤差值。以此為基礎,對各種預測模型的預(yù)測精度進行比較驗證不同模型(xíng)的(de)穩健性。結果表明,多元線性回歸算法的最小一乘、最小二乘估計模型以及分布滯後模型在改變試驗條件時預測精度下降,而基於支持向(xiàng)量回(huí)歸機原理的熱誤差補償模型仍能保持(chí)較好(hǎo)的預測精度,穩性強。這為數控機床熱誤差補償模型的選擇提供了具(jù)有實用價值(zhí)的參考,具有很好工程應用性。
關鍵(jiàn)詞:數控機床;熱誤差;穩健性;多元線性回歸模型;分布滯(zhì)後模型;支持向(xiàng)量回歸機
0 前(qián)言
在數控機床的各種誤(wù)差源中,熱誤差已經(jīng)成為影響零件加工精度主(zhǔ)要誤差(chà)來源。減少熱誤差是提高數控機床加工精度的關鍵。在熱誤差補償中,建模技術則是重點。由於機床熱誤(wù)差在很大程度上取決於加工條件、加工周期、切削液的使用以及周圍環境等等多種因素,而且熱誤(wù)差呈現非線性及交互作用,所以僅用(yòng)理論分析來精確建(jiàn)立熱誤差數學模型是相當困難的(de)。最為常(cháng)用的熱(rè)誤差建模方法為試驗建模法,即根據(jù)統計理(lǐ)論對熱誤差數(shù)據和機床溫(wēn)度(dù)值作相關分析。楊建國等提出了數控機(jī)床熱(rè)誤差分組優化建模,根據溫度變量之間的相關性對溫度變量進行分組,再與熱誤差進行排列組合逐一比較選出溫(wēn)度敏感點用於回歸建模。韓國的KIM 等運用有限元法(fǎ)建立了機床滾珠絲杠係統的溫度場(chǎng)。密執安大學的YANG 等運用小腦模型連接控製器(CMAC)神(shén)經網絡建立了機床熱誤差模型。
ZENG等用粗糙集人工神經網絡對數控機床熱誤差分(fèn)析與建模,並對(duì)建模精度進行了論證。Chen Cheng等運用聚類分析理論和逐步回歸選擇三坐標測量機熱誤差溫度敏(mǐn)感點,用PT100測量溫度、激光幹涉儀測量三坐標測量機熱(rè)誤差,建立(lì)了多元線性模型。由於這些建模方式是(shì)離線和預先建模,而且(qiě)建模數據(jù)采集於(yú)某段時間,故用這些方法(fǎ)建立起來的熱(rè)誤差數(shù)學模型的穩健(jiàn)性顯然不夠,一般隨著季節的變(biàn)化難以長期正確地預報熱誤差。近年來,支持向量機是發展起來的一種專門研究小樣本(běn)情況下的機器學習規律理論,被認為是針對小樣本統計和預測學習(xí)的最佳理論。支持(chí)向量機建立在VC維理論(lùn)基礎上, 采用結構風險最小化原則, 不僅結構簡單, 且有效解決(jué)了模型選擇與欠學習、過學習、小(xiǎo)樣本(běn)、非線性、局部最優(yōu)和(hé)維數災難等問題(tí),泛化能力大大提高(gāo)。本文對Leader way V-450型數控加工中心進行熱誤差測量試驗,采用模糊聚類(lèi)與灰色關聯度理(lǐ)論綜合應用進行了溫度敏感點選擇,同時利用(yòng)多元線性回歸模型,分布滯後(hòu)模型,支持向量回歸機(jī)模型分(fèn)別建立熱誤差補償模型,並對多元回歸模(mó)型分別采(cǎi)用最小二乘和(hé)最小一乘估計,通過比對各種模型的穩健性,從而為數控機床熱(rè)誤差補償建模方法的選(xuǎn)擇提供了參考,具有實際的工(gōng)程應用價值。
1 熱誤差建模模型
1.1 多元線性(xìng)回歸模(mó)型
多元線性(xìng)回歸(guī)(MLR)是一種用統計方(fāng)法尋求多輸入和單(dān)輸出關係的模型。熱誤差的多(duō)元線性回(huí)歸模(mó)型以多個關鍵溫度敏感點測(cè)量的溫度增量值為自變量,以熱變(biàn)形量為因變量,其通(tōng)用(yòng)表達式為
式中, 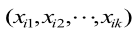 為關鍵溫度敏感點溫度測量(liàng)增量值,
為關鍵溫度敏感點溫度測量(liàng)增量值, 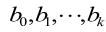 為溫度變量的係數,y i 為熱變形測量(liàng)值, ei是與實際測量值 yi存在(zài)的偏差,也稱(chēng)殘差。
為溫度變量的係數,y i 為熱變形測量(liàng)值, ei是與實際測量值 yi存在(zài)的偏差,也稱(chēng)殘差。
同時,采用最小(xiǎo)一乘和最小二(èr)乘(chéng)兩種準則對線性回歸模(mó)型進行估計計算。最小二乘法在方法上較為成熟,在理論上也較(jiào)為完善,是一種常用的最優擬合方法,目前廣泛應用於科學技術領域的許(xǔ)多實際問題中(zhōng),在數控機床(chuáng)建(jiàn)模技(jì)術中(zhōng)也有很多的應用。而最(zuì)小(xiǎo)一乘法受異常值的影響較小,其穩健性比最小二乘法的要好,但最小一乘回歸屬於不可微問題,計算具有較大的(de)難度。文中針對最小一乘的算法采用文獻[13]的算(suàn)法理論和 Matlab 程序。 最小二乘準則——殘(cán)差平方和最小,即(jí)
最小一(yī)乘準則——殘差絕對值和最小,即
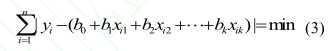
1.2 分布(bù)滯後模型
如果因變量不僅(jǐn)與一個或多個解釋變量的(de)當前值有關係而且與其若幹滯後值(zhí)有關係(xì),描述這種關係的模型稱為分布滯後模型(DL),記為 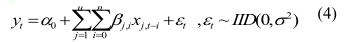

對於滯(zhì)後階數 n 的(de)確定,由於試驗測(cè)量(liàng)數據量比較大,所(suǒ)以可以采用簡單的權宜估計法。即取n=1,2,…,i,對(duì)不(bú)同的 i 條件下經最小二乘擬合(hé),當(dāng)滯後變量的回歸係數開始(shǐ)變得統計不顯著, 或(huò)其中有一個變量的係數改變符號時,i-1 就是(shì)最終的滯後階數。
1.3 ε- 支持向(xiàng)量回歸機模型 (SVR)
統計學習理論是由 VAPNIK[11]建立的一(yī)種專門研究有限樣本情況下(xià)機器學習規(guī)律的理論,支持(chí)向量機是在這一理論基礎上發(fā)展起來的一種新的分類和回歸工具。支持向量(liàng)機通(tōng)過結構風險最小化原理來提高泛化能力,並能較好地解決小樣本、非線性、高維數、局部極小點等實際問題,其已在(zài)模式識(shí)別(bié)、信號處理(lǐ)、函數逼近(jìn)等領域應用。
1.3.1 ε-支持向量回歸機(jī)的原理
根據結構風險(xiǎn)最小化原理,ε-支持向量回歸機的(de)函數建模問題(tí)就是尋找使下麵目標函數風險
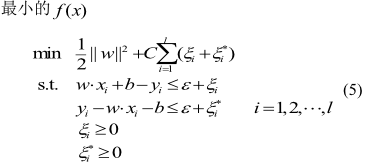

優(yōu)先選擇高斯徑向基(jī)核函數(shù)用於熱誤差建模。當(dāng)選用(yòng)高斯徑(jìng)向基核(hé)函數時,訓練結果精度以及(jí)穩健性取決於g和C的取值。支(zhī)持向(xiàng)量機參數選擇方法通常包(bāo)括基於網絡遍曆尋參算法、交叉(chā)驗證法等,而交叉(chā)驗證(zhèng)方法應用比較簡單、實用(yòng)性強(qiáng),本文根據交叉驗證法優化模型參數[14]。
2 試驗設計
2.1 試驗方案
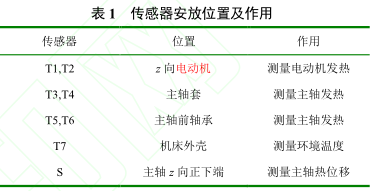
本文對 Leader way V-450 數控加工中心主軸 z向進(jìn)行熱誤差(chà)測量試驗(yàn),各傳(chuán)感器的安放位置及作用如表 1 所示,溫度傳感器和電感測微儀具體分布位置如圖 1 所示。

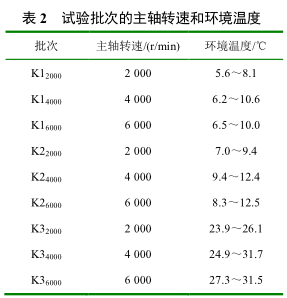
試驗對數(shù)控加工中心在不同季節(不同環境(jìng)溫(wēn)度)、不同主軸(zhóu)轉速下進行了九次(cì)熱誤差測量試驗,測量的次(cì)數、轉速及環境溫度(dù)如表 2 所示。

2.2 溫度敏感點的篩選
為便於實際工(gōng)程應用,針對(duì)溫(wēn)度傳感器數目進行優化挑選,合理有效地篩選溫度傳感器有助(zhù)於提高機床熱誤差建模精度。本文采用模糊聚類與回歸關聯度相結合的方法選擇熱誤差關鍵敏感點,具體方法,最終選擇 T6 和(hé) T7 作為溫(wēn)度敏感點。
3 建模(mó)模型的穩健性分析
穩健性是指在(zài)模型與實際對象存(cún)在(zài)一(yī)定差距時,模型依(yī)然具有較滿意的模擬預測性能。本文利用多元線性回歸的最小二(èr)乘、最小(xiǎo)一乘估(gū)計模型,分布滯後(hòu)模型以及支持(chí)向量回歸機模型對 K16000數據分別建立預測模型,先進行各模型對(duì)本批數據的擬合精度進行分(fèn)析,隨(suí)後將該模型用於其他批(pī)次采樣數據的預測,以判斷模型的穩健性。同時,根據建模數據的來源(yuán)批次特征,對各算法給予了穩健性分析。
3.1 不同算法的模型擬合精度(dù)分析
各個模型的數學公(gōng)式如下。
MLR 最(zuì)小二乘估計公式
式中,T6為(wéi) T6 處(chù)溫度增量;T7為 T7 處溫度(dù)增量。
MLR 最小一乘估計公式 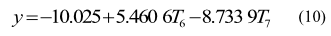
式中(zhōng),T6為 T6 處溫度增量,T7為 T7 處溫度增量。DL 模型公式:由權(quán)宜(yí)估計法判斷分(fèn)布滯後模型的後階(jiē)數為二階

式中,通(tōng)過交叉驗證(zhèng)方法(fǎ)優化參數敏感函(hán)數(shù)g=0.002 6,懲罰係數 C=24 834;通過軟(ruǎn)件 LIBSVM在 Matlab 上運行,可以得到支持向量、支持(chí)向量(liàng)對應的係(xì))以及常數(shù)項 b=49.551,l為數據量(本批次為 110 個)。 各模型對 K16000數據擬合標準差如表(biǎo) 3 所示,擬合效果如圖 2 所(suǒ)示。
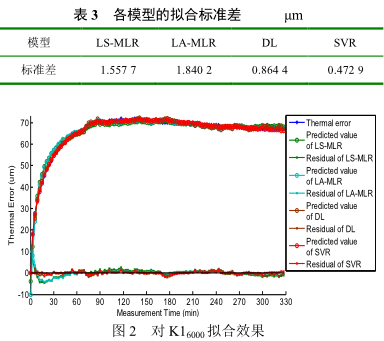
由表 3 可知,擬合精度 SVR 最優(yōu),DL 其(qí)次,擬合精度最差的是(shì) MLR 最小一乘算法。為比對各算法穩健性,利用各個模型建立的預測模型對其餘批次數據按照(zhào)同轉速不同溫度(環境溫度變化範圍較大)、同溫度(環境溫度變化較小)不同轉速(sù)不同溫度(環(huán)境溫度變化範圍較大)不同轉速三種類型進行數據預測,根(gēn)據預測效果對各個補償模型進行穩(wěn)健性分析。
3.2 同轉速不同環境溫度分析
以 K16000數據建立的預測模型對 K26000數據進行預測精(jīng)度分析,分析效果如圖(tú) 3 所示;再對K36000數據進行(háng)預測精度分析,分析效果(guǒ)如圖 4 所示。各(gè)個(gè)預測模型的預測標準差如表 4 所示。
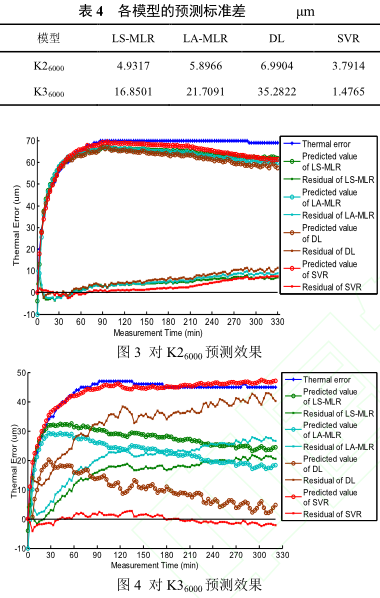
通過分析比(bǐ)較可得,轉速(sù)不變,環境溫度增加較小時,各個預測模型的預測效果仍然保持較好,但是隨著環境溫度增(zēng)加較大時,多元線性回歸(guī)的最(zuì)小二乘、最小一乘模型以及分布(bù)滯後模型的預測效果變差,其中多元線性回歸的最小二乘(chéng)算法相對較好,隨後是最小一乘模型(xíng),預測效果最差的是分布滯後(hòu)模(mó)型。除此之外,支持向量回歸機模型仍能保持很好的預測精度。
3.3 同溫度不同轉速分(fèn)析
針(zhēn)對溫度(dù)變化範(fàn)圍(wéi)較小的不同轉速測量數據,以 K16000數據建立(lì)的預測模型對K14000和 K12000數據進行(háng)預測精度(dù)分析,根據分析數據結(jié)果來判(pàn)斷不同算法建立的模型的穩健性。先對 K14000數(shù)據進行分析,分(fèn)析效(xiào)果如圖 5 所(suǒ)示;然後分析 K12000數據,分析效果如(rú)圖 6 所示。各個預測模型的預測標準差如表 5 所示。
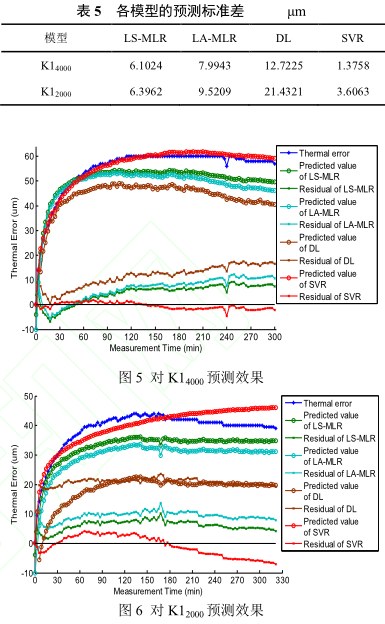
通過分析比較可得,環境溫度基本不變,轉速逐漸降低時,最小二乘和最小一乘模型仍具有一定的預測精度,分布滯後模型預測效果(guǒ)越來越差,而(ér)支持向量回歸機模型始終保持很好的預測精度。各(gè)算法穩定性(xìng)優劣依次為支持向量回歸機模型、最(zuì)小二乘、最小一乘和分布滯(zhì)後模型。
3.4 不同溫度(dù)不同轉速分析
針對環境溫度變化時的不同(tóng)轉速測量(liàng)數據,以 K16000數(shù)據(jù)建立的預測模型對 K24000、K22000、K34000和 K32000數據進行預測精度分析,根據分(fèn)析數據結果來判斷不(bú)同算法建立的模(mó)型的穩健性。各個預測(cè)模型(xíng)的預測標準差如表 6 所示。


通過分析比較可得,環境溫度變化幅度較小,轉(zhuǎn)速逐漸降低時(shí),最小二乘和支持(chí)向量回歸機模型具有很好的預測(cè)精度,最小一乘模型的預(yù)測精度(dù)逐漸降低,分布滯(zhì)後模型預測效果逐漸變差;環境溫度變化幅度較大時(超過 10℃),轉速(sù)逐漸降低時(shí),隻有支持向(xiàng)量回歸機模型仍保持較好的預(yù)測精度(dù),其他的預測(cè)模型(xíng)的預測效果(guǒ)很差。各算法穩定性優劣依次(cì)為支持向量回歸機模型、最小二乘、最小一乘和分布滯後模型。
4 結論(lùn)
(1) 通過長期測量數控機床(chuáng)熱誤差和關鍵敏感點溫度來獲得多批次的(de)試驗數據,通過多種模型算法進行了預測建模,從機床主(zhǔ)軸同轉速不同環境溫度、同環境溫度(dù)不(bú)同轉速、不(bú)同轉(zhuǎn)速不同環境溫(wēn)度等(děng)三種情況對預測(cè)模型的精度與(yǔ)穩定(dìng)性進行了分析。
(2) 從試驗(yàn)效果可知,分布滯後(hòu)模(mó)型具有很好的擬合精度,但以一組采樣數據建立的分布滯後(hòu)模型其穩健性較差。僅以一組采樣(yàng)數據進(jìn)行建模,最小(xiǎo)一乘模型(xíng)的穩健性並不優於最小(xiǎo)二乘模型(xíng),反而略(luè)差。最小一(yī)乘法穩健性高(gāo)於最小二乘法的說法,是基於對異常數據處理方麵的優勢,而數控機床(chuáng)熱變形測量數據中出現異常數據的概率很小,使得(dé)該(gāi)法的優勢並未得到體現,而且數控(kòng)機(jī)床熱誤差數據(jù)樣本量(liàng)較大,最小一乘算法複雜,相對於最小(xiǎo)二乘法,最小一乘法在數控機床熱誤差預測建模中(zhōng)的實際應用效果反而不如最小二乘法。
(3) 支持向量回歸機(jī)模型擬合精度高,預測效果(guǒ)保持性好,穩健性(xìng)強(qiáng),該算法作為數控機床熱誤差補償的建模算法具有工程應用(yòng)基礎。
投稿箱:
如果您有機床行業、企業相關新聞稿件發表,或進行資訊合作,歡迎聯係本網編輯部, 郵箱:skjcsc@vip.sina.com
如果您有機床行業、企業相關新聞稿件發表,或進行資訊合作,歡迎聯係本網編輯部, 郵箱:skjcsc@vip.sina.com
更多(duō)相關信息

業界視點
| 更多

行業數據(jù)
| 更多
- 2024年11月 金屬切削機床產量數據
- 2024年11月 分地區金(jīn)屬切削機床產量(liàng)數據
- 2024年11月 軸承出口情況
- 2024年11月 基本型乘用車(轎車)產量數據
- 2024年11月 新能源汽車產量(liàng)數據
- 2024年11月(yuè) 新能源汽車銷量情況
- 2024年10月 新能源(yuán)汽車產量數據
- 2024年10月 軸(zhóu)承(chéng)出(chū)口情況
- 2024年10月 分地區金屬切削機床產量數據
- 2024年10月 金屬切削機床產量數據
- 2024年9月 新能源汽(qì)車銷量(liàng)情況
- 2024年8月 新能源(yuán)汽車產量(liàng)數據
- 2028年8月 基本型乘用車(轎(jiào)車)產量數據
博文選萃
| 更多