



數控係統可靠性數據壓縮(suō)算法
2018-8-6 來源:轉載 作者:林新然,王力傑,劉 峰,張兆中
摘要: 數(shù)控係(xì)統可靠性數據是產品早期故障定位(wèi)和(hé)排除的基礎. 數控係統包(bāo)含配置數據,診斷數據,運行狀(zhuàng)態數據等可靠性數據,這些數據大(dà)部分是實時數據,隨著(zhe)監測時(shí)間的推移會大量增長,所以數據(jù)的有效存儲是不得不解決的問(wèn)題. 數據(jù)壓縮是節省存儲空間、提高存儲(chǔ)效率的(de)一種有效方法(fǎ). 根據不同類型(xíng)可靠性數據的特點和變化規律,設計合適的(de)壓縮算法. 改進 LZW 算法實現靜態文本數(shù)據的壓縮,改進旋轉(zhuǎn)門算法壓縮過程數據,對網絡傳輸數據采用二級壓縮方式進行壓縮. 實驗表明,使用該壓縮方案能夠在(zài)保證實時性的情況下對數控係統(tǒng)不同類型的可靠性數據進行有效(xiào)的(de)壓縮,節約存儲空間和(hé)網絡傳輸帶寬.
關鍵詞: 數控係統; 可靠性數據; 有(yǒu)損壓縮; 無損壓縮(suō); 不同(tóng)類型數據
1、引 言
數控係(xì)統作為各類數控機床的(de)控製(zhì)中樞(shū),被稱為機床的靈魂和大腦,它的可靠性是(shì)製約高檔(dàng)數控機床發展的重要因素. 數控係統可靠(kào)性(xìng)數(shù)據是提高(gāo)產品可靠(kào)性的基礎(chǔ),對早期故障的定位和排除、以及新產品的研發(fā)起到了關鍵的(de)指導作用(yòng).
數控係統可靠性數據結合可靠性仿真技術、分布式控製技術、網絡化監測技術、維修策略優化技(jì)術等是(shì)提高數(shù)控係統可靠性的有效途徑.數控係統采集的可靠性數據主要包括: 設備信息數據(jù)、配置數據、運行狀(zhuàng)態數據、診斷數(shù)據(jù)等,根(gēn)據數(shù)據特點和作用大致可以分為靜(jìng)態數據、觸發類數據、時間值、過程數據和網絡傳輸數據.
靜態數據包括設備信息、配置數據、診斷數據等(děng); 其中設(shè)備信(xìn)息包(bāo)括數控係統型號、編號、軟件版本、硬件各(gè)部件(jiàn)版本(běn)等; 伺服和(hé)電機型號、編號、軟件版(bǎn)本、硬件版本等; 機床型號、編號等數(shù)據. 配置數據包括數控係統和伺(sì)服的參數、用戶加工程(chéng)序等. 診斷數據包括硬件診斷(duàn)信息、軟件診斷信息、伺服運行診斷信息等.
觸發類數據包括開關量,工作方式,工作狀態等.
過(guò)程數據(jù)主要包括軸坐標、進給速度(dù)、進給倍率、電流、溫度(dù)、濕度等數(shù)據.
網絡(luò)傳輸數(shù)據是需要傳輸到遠程第三方的實時數據.
數控係統運行(háng)狀態數據的采集周期為 10ms,一(yī)台機器每天(tiān)的數據量大概是 600MB,一個(gè)月的數據量(liàng)就是 18GB,長期保存(cún)這些數據需要相當大的存儲空間. 為了確保可靠性數據能夠實時存儲,並且盡可能的節約存儲空間和成本(běn),減少網絡傳輸中占用的(de)帶寬(kuān),需要對不同類型的可靠性數據進行壓縮處理(lǐ).不同類型的可靠性(xìng)數據(jù)具(jù)有不同的特點,靜態數(shù)據主要是描述性的文本數據,上下文有一定(dìng)的聯係; 觸發類數據是在一(yī)定(dìng)時間內保持(chí)相同狀態的數據; 而(ér)過程數據是具有一定變化規律的浮(fú)點型數據.一種壓縮算法對不同類型數據的壓縮效果是不同(tóng)的,數控係統可靠性數據不是(shì)單一類型,所以本文針對這五類可靠性數據的特點和變化規(guī)律,實現了一(yī)種有效的壓縮方案: 改進LZW 算法壓縮靜態數據,采用 RLE 算法壓(yā)縮觸發類(lèi)數據和時間值,改進旋轉門算法壓縮過程數據(jù),采用二級壓縮方(fāng)式壓縮網絡傳輸數據.
2 、數據壓縮算法
數據壓縮算法按其壓縮精度,可以(yǐ)分為有損壓縮和無損壓縮. 有損壓縮是通過一定的篩(shāi)選條件來判斷是否保存數據,在壓縮過程中會舍棄一部分數據,但這(zhè)些數據對原始數據的恢複影響不大(dà),具有較高(gāo)的壓(yā)縮率(lǜ). 無損壓縮(suō)利用數據的統計冗餘來進行壓縮,能夠(gòu)完全(quán)恢複原始數(shù)據而不引起任何失真,但是壓縮率受(shòu)到數據(jù)統(tǒng)計冗餘度的(de)理論限製.常用的無損數據壓縮算法有(yǒu) Huffman 編碼算法、遊程編(biān)碼算(suàn)法,LZ 係(xì)列編碼算法等. 針對(duì)工業過程數據的有損壓縮方法可以分為 3 類,即分段線性方法、矢量(liàng)量化(huà)方法以及信號變換法. 分段線性方法又包括矩形(xíng)波串法、後向斜率法、旋轉門算法及 PLOT 法.
2. 1 Huffman 編碼算法(fǎ)
Huffman 編碼是一(yī)種基於統計模型的可變字長(zhǎng)編碼,根據原始數據中(zhōng)不同字符出現的不(bú)同概率進行編碼,對於出現概率較大的字符采用較短的編碼,出現(xiàn)概率較小的字符采用較長的編碼(mǎ),使整體數據的平均編碼達(dá)到最短. Huffman編碼算(suàn)法的缺點是,由於需要統計原始(shǐ)數據中字符出現的概率後,根據字符(fú)出(chū)現的概(gài)率構建出 Huffman 樹才能對數據進行編碼,所以需(xū)要掃描兩次原始數據,這會消(xiāo)耗較多(duō)的時間.
2. 2 遊程編碼算法
遊程編碼也是一種基於統計(jì)模型的編碼方法,是對連續出現多次的字符進行(háng)編碼,用串長和字符值代替(tì)連續的字符. 遊程編(biān)碼不像 Huffman 編碼需要掃描兩遍原始數據,隻需對原始數據一(yī)次掃描(miáo)就可以完成編碼(mǎ),並且實現(xiàn)起來比較簡單(dān). 遊程編碼(mǎ)的缺點是隻對具有大(dà)量連續字符的數據(jù)有較好的壓縮(suō)效果,對普通的文本數據壓縮效果比較差.
2. 3 LZ 係列編碼
LZ 係列(liè)編(biān)碼是基於字典模型的(de)編碼方法,這種模(mó)型的(de)編(biān)碼方法可分(fèn)為兩類. 第一類的思想是查找(zhǎo)正(zhèng)在壓縮的(de)字符串是否在前麵壓縮過(guò)的數據流中出(chū)現過,如果是(shì),則用指向出現(xiàn)過字符串的“指針”代替重複的字(zì)符串,以 LZ77 算法和 LZSS算法為代表. 這類算法在窗口(kǒu)中查(chá)找(zhǎo)最長匹配(pèi)字符串是一個比較複雜的過程(chéng),會消耗較多的時間,並且(qiě)由於窗口的大小是有限的,對具有(yǒu)較長匹配(pèi)的數據的壓縮效果(guǒ)不是最(zuì)佳.第二類的思想是從輸入的數據中創建一個“字典”. 當數據壓縮過程中(zhōng)遇到已經在詞典中出現的字符串時,就以字符串(chuàn)在字典中的 “指針(zhēn)”代替重(chóng)複的字符串(chuàn),以 LZ78 算法和LZW 算法為代表. 這類算(suàn)法(fǎ)需要(yào)在壓縮過(guò)程中逐步構建“字典(diǎn)”,這就需要一定的存(cún)儲空間,而且難以快速適應原始數據的特點.
2. 4 旋轉門算法
旋轉(zhuǎn)門壓縮算法的(de)原理是通過查看當前(qián)值和(hé)最後保存的值所構成的壓縮偏移覆蓋(gài)區,決定是否(fǒu)保存待(dài)壓縮值. 如果該覆蓋區可(kě)以覆蓋兩者之間的(de)所有點,則不保留兩者之間的所(suǒ)有點,如果兩者(zhě)之間有數據點落在該覆蓋區之外,則保留前一個時間點的值,並以該時間點的值作為最後一個被保存值. 該算法是一種壓縮能力強(qiáng)、壓縮效果好的(de)實時數據(jù)有損壓(yā)縮算法.
3 、數控係統可靠(kào)性數據的壓縮算法
數控係統可靠性數據歸納為靜態數據(jù),觸發類數據(jù),時間值,過程數據以(yǐ)及網絡傳輸數據. 不同的壓縮算法對數據的壓縮效率是不(bú)同的,如果不考(kǎo)慮數據的特點(diǎn),對所有的(de)數據都采用同一種壓縮算法,會大大(dà)降低數據的壓縮效率. 所以本文分(fèn)析數控係統不同類型數據的特點以及變化規律,針對不同類型數據分別設計(jì)有效的壓縮算法以實現數據的高效存(cún)儲.
3. 1 靜態數據
從數控係統采集的靜態數據包括數控係統型號、編(biān)號、軟件 版本、硬件各部件版本,數控係統和伺服的參數,硬件診斷信息、軟(ruǎn)件診斷(duàn)信息等數據. 分析發現這些數據中包含一些出現頻率很高的詞條,比如: 係統型號(hào),故障類型,故障位置等.算(suàn) 法 基 本 流 程( 見圖 1) .

圖 1 靜態文本數據壓縮流程圖
LZW 算 法 是 一種(zhǒng)高效的無損壓縮(suō)算法,並且在壓縮(suō)過程中不需要查找匹配字符串,這點在算法(fǎ)實現上比 LZSS 簡單許多,但 是 LZW 算 法是在(zài)壓縮過程中逐步建立的(de)字典,其對原始數據特點的自適應過程(chéng)較為緩(huǎn)慢,所以結合 LZW 算法針對數據(jù)特點做了簡單改進,在對原(yuán)始數(shù)據編(biān)碼之前首先利用名詞字符串對字典初始化,這些名詞字符串(chuàn)由出現頻率較高的名詞條組成,然後利用LZW 算法進行壓縮,相當於組合使用了靜態字典和(hé)動態字典,這就解決(jué)了 LZW 算法字典自適應過程(chéng)較慢的問題.
3. 2 觸發類數據和時間值(zhí)
在數控係統數據(jù)中存在像開關量(liàng)型的觸發類數據,以及具有周期性的時間值. 在對時間值差值處理後(hòu),這些數據都具有(yǒu)大量的連續字符,上文提到遊(yóu)程編碼對具(jù)有大(dà)量連續字符的數據(jù)有相當好的壓縮效果,所以針對這類數據采用遊程編(biān)碼算法會得到較高的壓縮率(lǜ).遊程編碼在處理不連(lián)續重複的字符時,會存儲兩個字節( 串長,字符) ,而原字符隻有(yǒu)一個字節,也就是說使用遊程編碼處理這些不連續重(chóng)複數(shù)據反而加大了存(cún)儲空間,所(suǒ)以本文采用 PCX 文件中改進的 RLE 算法,將不重複的字符直(zhí)接存入壓縮(suō)文件,利(lì)用字節的高兩位來(lái)區分是原數據還是壓縮編碼,高兩位全為 1 代表串長,高兩位不全為 1 代表原字(zì)符.算法(fǎ)基本流程( 見圖(tú) 2) .
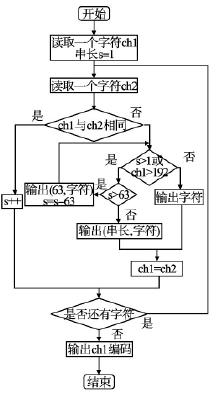
圖 2 觸發(fā)類(lèi)數據壓縮流程圖(tú)
3. 3 過程數據
數(shù)控(kòng)係統數據包含(hán)大量的運行狀態數據,主要是軸坐標、進(jìn)給速度、電流等(děng)過程數據. 由於旋轉門算法實(shí)現簡單,執(zhí)行速(sù)度快,壓縮效率高,所以在過程工業中較(jiào)多利用該算法進行數據壓縮. 但是數控係統可靠性測試的過程數據的壓縮需要最大可能的(de)保持原數據的特點,也就是說為了可靠性的評估和測試,對一些偏差數據也要保存下來,同時又不能影響到正常(cháng)數據的解壓恢複,所以不能直接應(yīng)用旋轉(zhuǎn)門算法對這些數據壓縮(suō).
旋轉門算法根(gēn)據當前值和最(zuì)後保存的值所構成的(de)壓縮(suō)偏移覆蓋區是否可(kě)以覆蓋兩者之(zhī)間的所有點,來決定是否保留前一個時間(jiān)點的值,它不能夠對偏差數據進行處理,所(suǒ)以需要對其進行改(gǎi)進以滿足可靠性測試(shì)的需求(qiú). 主要改進點: 設定一(yī)個判斷偏差(chà)數據的閾值,若數據與預測(cè)數據之差超過閾值,則認定為偏差(chà)數據,需要保存. 並且(qiě)為了確保解(jiě)壓時數據的準確性(xìng),對(duì)偏差數據的(de)前後兩個數據也需要存儲,使解壓數據不受偏差數據的影響. 如果為(wéi)了判斷數據是否是偏差數據,而對每一個數據都計算預測值,會耗費較多(duō)的時間(jiān),這就(jiù)需要根據一定的方(fāng)法來減少計算量. 分析發現: 偏差數據隻可能在保存數據的後一個(gè)數據出現,也就是和最後保存的值所構成的覆蓋區不可(kě)以覆蓋兩者之間所有點的(de)那個數據,隻需要對這些數據計算其預測值,分析是否是偏差數據. 預測值則利用前一個保存數據和偏差數據的前一個數據的線性外插法來(lái)計算. 為了進一(yī)步提高存儲效(xiào)率,可以(yǐ)提(tí)前對數據進(jìn)行差值預處理後壓縮.算法基本(běn)流程( 見圖 3)
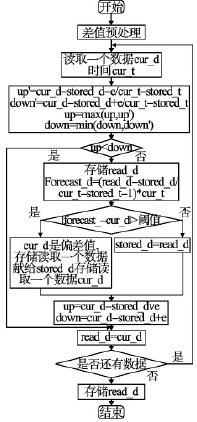
圖 3 過(guò)程數據壓縮流程圖
3. 4 網絡傳輸數據
從數控係統實時采集到的數據需要(yào)通過一定的格式(shì)及時的(de)發送到遠程進行處理,為了節約網絡帶寬(kuān),減少傳輸時間,有必要(yào)對網絡傳輸數據進行壓縮處理. 本文的數據傳輸格式采用 XML 格式,為(wéi)了描述數據的意義,不(bú)同的數據需要(yào)不同的 XML 標簽,在標簽中包含(hán)不同類型的數據,顯然該類數據的上(shàng)下(xià)文關聯性不強.一般采(cǎi)用無損壓(yā)縮算法壓縮文本數據(jù),其中 LZ係列算法對於(yú)上下文關聯性較強的數(shù)據(jù)能夠取得較好的壓縮效果,所以該類型數(shù)據利用 LZ 係列算法不能夠(gòu)獲得較(jiào)好 的 壓 縮率. Huffman 編碼對字(zì)節(jiē)進行統(tǒng)計編碼,需要掃描兩次原始數據,會(huì)消耗較多的時(shí)間,不適合直接用於壓縮數據. 通過分析利用 XML 格(gé)式傳輸的網絡數據,發現 XML 標簽內字符串的出(chū)現(xiàn)頻率較高且比較固定,所以可以通過靜態(tài)字典(diǎn)的方式首(shǒu)先對(duì)這些字符串壓縮以及字符統計,再通過Huffman編碼進行壓(yā)縮(suō),通過這(zhè)種靜(jìng)態字典和 Huffman 編碼結合的(de)方式對數據(jù)二級壓縮可(kě)以解決壓縮率(lǜ)較低的問題,並且相比 Huffman 編碼減少了(le)壓縮時間.算法基本流程( 見圖4)
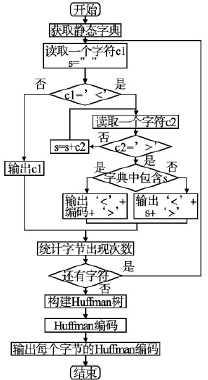
圖 4 網絡傳(chuán)輸數據壓縮流程圖
4、 算法效率測試
原數(shù)據都存儲在文件中(zhōng),所以壓縮過程中會不斷地(dì)從文件(jiàn)中讀寫數據,這會對壓縮和解壓時間有一(yī)定的影響. 壓縮算法的優劣主要從三個方麵來判斷: 壓縮(suō)率、絕對誤差、和時間,所以對(duì)無(wú)損壓縮算法的測試主要包括壓縮時間(jiān)、解壓時間、壓縮率,對有損壓縮算法的測試(shì)主要包括壓縮(suō)時(shí)間、解(jiě)壓時間、壓縮率、絕對誤差.


CR 是壓縮率,M 是壓縮後文件大小,N 是原文件大小.AE 是絕對誤差,yn是原文件數據,yn是壓縮文件恢複數據,n是數據個數. 時間代表壓縮時間(jiān)和解壓時間.
4.1 靜態數據壓縮效率
實驗通過使用 LZW 算法、LZSS 算法、以及(jí)改進的 LZW算(suàn)法分別對靜態數據進行壓縮測(cè)試(shì),表 1 為測試結果.
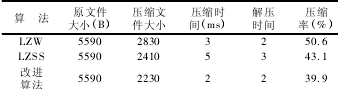
表 1 靜態數據在不同壓縮算法下的(de)壓縮效率
由測試結果看出,結合靜態字典的 LZW 算法減少了對出現頻率較(jiào)高(gāo)的名詞字符串逐步建立字典的過程,使這些字符串能夠直接編碼壓縮,而不需要逐步加(jiā)入字符的自適應過程. 相對於 LZSS 和(hé) LZW 算法降低了壓(yā)縮時間,提高了壓縮率,具有較好的壓縮效(xiào)果.
4. 2 觸發類數據壓縮效率
根據觸發類數據的特點,對其使用 PCX 文(wén)件的 RLE 算(suàn)法和 RLE 算法進行壓縮測(cè)試,結果如(rú)表(biǎo) 2 所示.

表 2 觸發類數據的壓縮結(jié)果
由測試結果看出,由於觸發類數據具有大量連續的字符,所以(yǐ)使用 PCX 文件的 RLE 算法獲得了較高的壓縮率. 並且通過對(duì)不連續字符的壓縮改進,相比原始(shǐ) RLE 算法又進一步提高了壓縮率. 對時間值進行差值預處理後獲(huò)得的數據具有連(lián)續性(xìng)特點,應用該 RLE 算法壓縮也獲得了(le)很(hěn)好的壓縮效果.
4. 3 過(guò)程數據(jù)壓縮效率
實驗對從數控係統采集到(dào)的坐標位移數據使用(yòng)旋轉門算法和改進的旋轉門算法進行壓縮(suō)測試,其中在 t = 100 和 t =1000 處設置了偏差點,壓縮(suō)結果如表 3 所示.
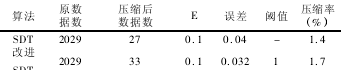
表 3 過程數(shù)據(jù)壓縮結果
由表 3 測(cè)試結果(guǒ)看出,改(gǎi)進的旋轉門算法和旋轉(zhuǎn)門算法同樣達(dá)到了(le)很好的壓縮結果,並且由圖 5 和圖 6 對比可以發現(xiàn)改進算法對第一個偏差點進行了(le)特殊(shū)處理,對超過閾值的偏(piān)差點保存,並且對偏差(chà)點的前後相鄰數據也保存處理,使其在解(jiě)壓時並沒有影響到其他數據的恢複,使數據的絕對(duì)誤(wù)差(chà)保持在一定範圍,而(ér)第二個數據沒有使用改進算法對偏(piān)差點處理,數據(jù)解(jiě)壓(yā)時會影響(xiǎng)到前(qián)後數據的恢複.
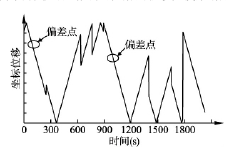
圖 5 過程數據壓縮前曲(qǔ)線圖
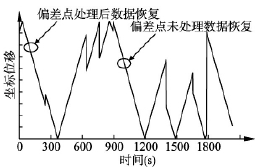
圖(tú) 6 過程數據解壓後(hòu)曲線圖
4. 4 網絡傳輸數據壓縮效率
實驗通過對網(wǎng)絡傳輸數據分別使用 Huffman 算法(fǎ),LZW算法,LZSS 算(suàn)法,以及靜態字典結合 Huffman 算法的(de)方式經行壓縮(suō),測(cè)試結果如表 4所示.
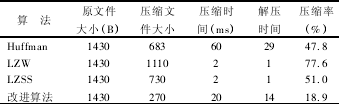
表 4 網絡傳輸數據(jù)在不(bú)同壓縮算法(fǎ)下的壓縮結果
由測試結果看(kàn)出,靜態字(zì)典編碼和 Huffman 編碼結合的二級壓縮方式比 Huffman 編碼的壓縮時間(jiān)縮短了很多,雖然相比 LZW 算(suàn)法和 LZSS 算法(fǎ)在壓縮和解壓時間上會有些不足,但是在壓縮率上具有較大優勢,對節約網絡帶寬很有幫助.
5、 結束(shù)語
數控係統的可靠性是製約數控係統發展的重要因素,數控係統的可靠性數據是可靠性測試的基礎,可靠性數據的有效存儲是必需的環節,數據壓縮是實現數據有效存儲的高效方法. 本文對數控係統不同類型可靠性數據設計(jì)了合適(shì)的壓(yā)縮算法,改進 LZW 算法壓縮靜態文本數(shù)據,采用(yòng) PCX 文件中改進的 RLE 算法壓縮觸發類數(shù)據和時間值,改進旋轉門算法壓縮過程數據,並且對網絡傳輸(shū)數據采用靜態字典和(hé) Huff-man 編碼(mǎ)的二級(jí)壓(yā)縮方式,實現了可(kě)靠性數據的高效存儲.
來源: 中國科學院大(dà)學 中(zhōng)國中材股份有限(xiàn)公司 中(zhōng)國科學院 沈陽計算技術(shù)研究所, 沈陽高精數(shù)控智能技術股份有(yǒu)限公司
投稿箱:
如(rú)果您有(yǒu)機床行(háng)業、企(qǐ)業相關新聞稿件發表,或進行資訊合(hé)作,歡迎聯係本網編輯部, 郵箱:skjcsc@vip.sina.com
如(rú)果您有(yǒu)機床行(háng)業、企(qǐ)業相關新聞稿件發表,或進行資訊合(hé)作,歡迎聯係本網編輯部, 郵箱:skjcsc@vip.sina.com
更多相關信息

業界視點
| 更多

行業數據
| 更多
- 2024年11月 金屬切削機床產量數據
- 2024年11月 分地(dì)區(qū)金(jīn)屬切削機床產量數據
- 2024年11月 軸承出口情況
- 2024年11月 基本型乘用車(chē)(轎車)產量數據
- 2024年11月 新能源汽車產量數據
- 2024年11月 新能(néng)源汽車銷量情況
- 2024年10月 新能源汽車產(chǎn)量數據
- 2024年10月 軸承(chéng)出口情況(kuàng)
- 2024年10月 分地區金屬切削機床產量數據
- 2024年10月 金(jīn)屬切削機床產量數據
- 2024年9月 新能源汽車銷量情況
- 2024年8月 新(xīn)能源汽車產量數(shù)據
- 2028年8月 基本型乘用車(轎車)產(chǎn)量(liàng)數據